Upwork RSS Feed [2024]
Oct 9, 2024
Replace the deprecated upwork RSS Feed by scraping Upwork in 2024

Replace the Upwork RSS Feed
Who can be interested?
If you used to use Upwork RSS feed to do automations that helped you to quickly identify the best job posts that suit your skills. If that's your case you will probably already know that Upwork closed the access to their job RSS feed the 20th of August 2024. In this blog we propose a solution for that.
If you spend a lot of time reading job posts to determine if the job suits your skills or not and you have considered at some point to automate that using LLMs like chatgpt (OpenAI). Well, actually it still applied if you are reading descriptions in general, no only job post description.
You do not have anything else to do and are curious about learning some new stuff :)
How do we get the jobs that were provided by the old Upwork RSS Feed?
Instead of using the old and deprecated RSS, Upwork has a specific URL that you can use to download the last posts available in the website. We wrote an entire article explaining how to do that. For the sake of simplicity here we just give a URL that can be used to get upwork jobs.
So far so good, thanks to this API we have access to the Upwork jobs without need to login.
How to automate the application of new jobs?
Thanks to this article we have the upwork job posts in a JSON. Now, it's time to consume this data and use it in some automations! Here your imagination is the limit, literally! You can program your automation in your favorite programming language or you can use some SaaS products like make.com or n8n.io (for those a bit more techy, n8n allows you to run your automations locally in a docker container).
In this tutorial, we have chosen make.com
Explain Automation
First download the Make Blueprint that we did for this tutorial (use the Download Blueprint link in this blog)
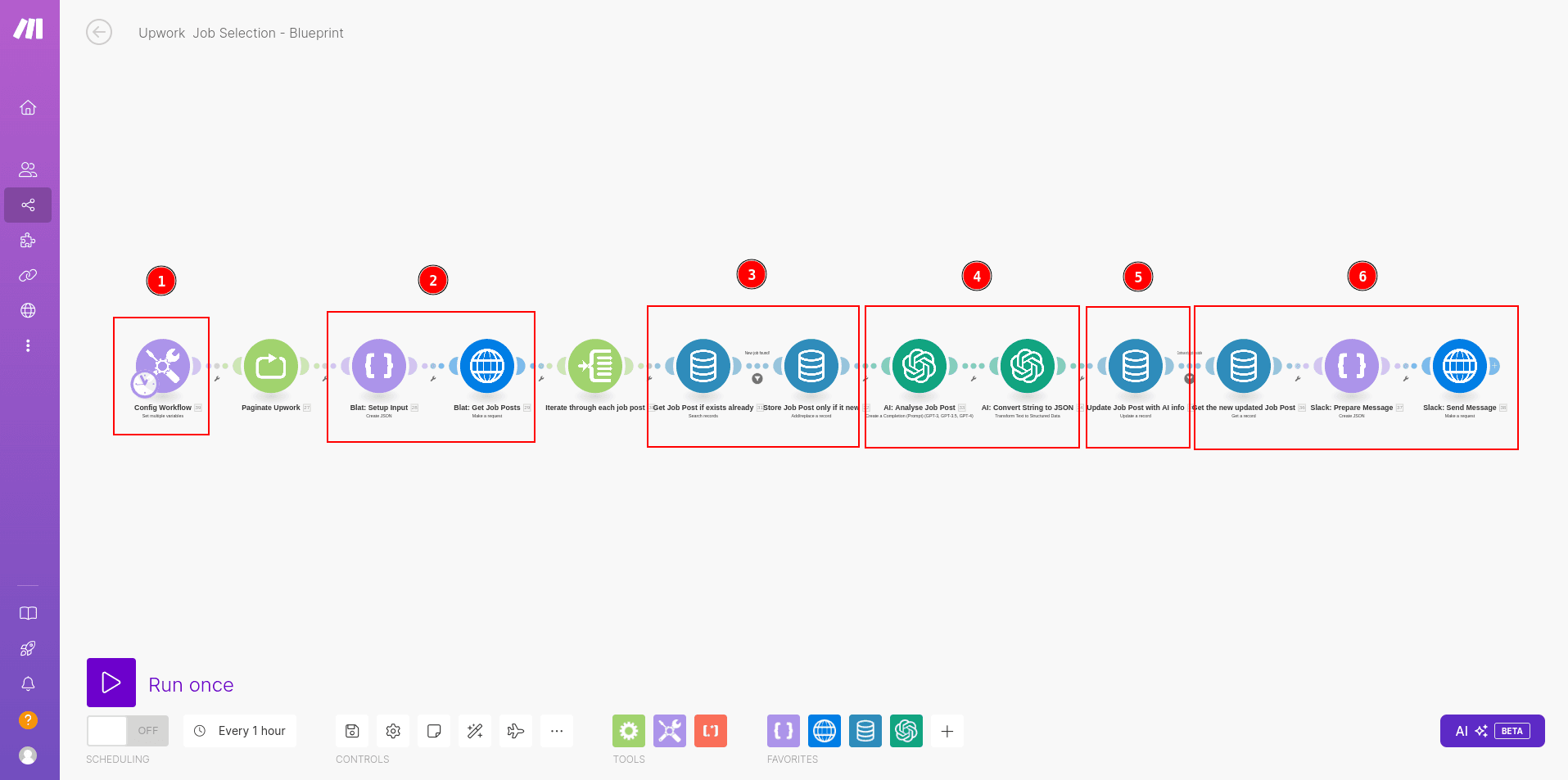
Config Workflow
You only need to configure the workflow defining some variables in the `Config Workflow` module. More information below about how to configure it.
Blat Data
Blat API is the one that gets the Upwork data and transforms it into JSON in a way it can be easily consumed by the rest of the workflow.
Save and find duplicates
The current workflow is intended to be executed periodically, so it quite possible that the same job offer is provided more than ones by Blat API. If that's the case, the current workflow detects it, finding duplicates and post-processing/saving only those jobs that are new.
AI Post-processing
Each job has a description. We use each `job description` together with the `freelancer description` and merge them in a Prompt where we ask if the job is suitable by the freelancer or not, explaining also why.
Update Job Post data with AI results
It might be interesting to save in the DB if the AI considered if the job was suitable or not by the freelancer and why.
Update Job Post data with AI results
Finally, it's time to send the results of those jobs that the AI considered that are suitable by the Freelancer. In this case, the job info is sent via Slack using slack webhooks. The same info could be sent in lots of different way, such as RSS, email etc.
Config Automation
We are defining each of the variables below:
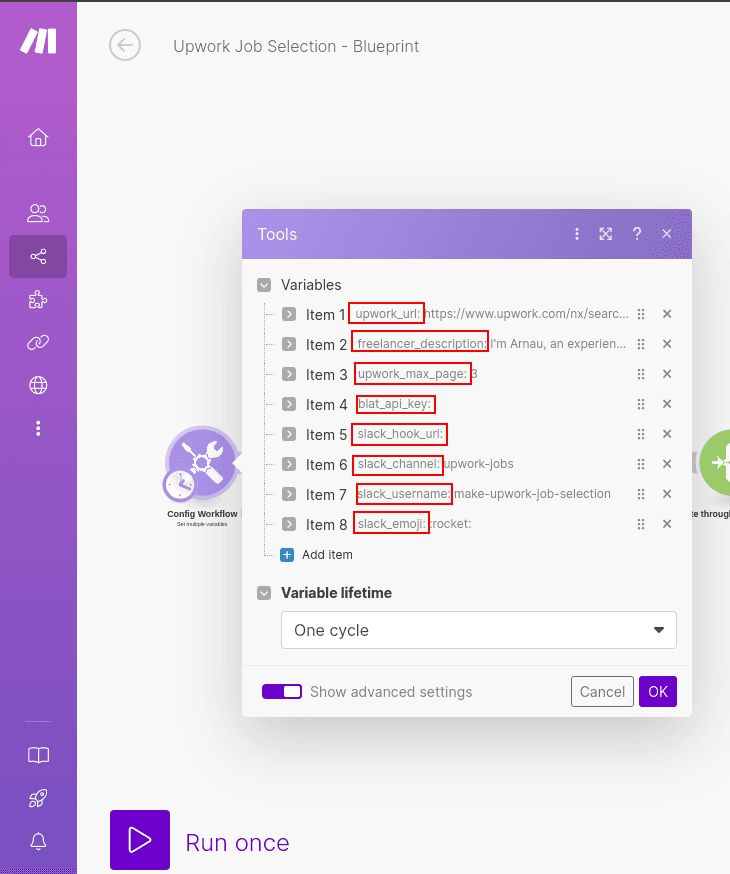
1) upwork_url: this is the url defined in the first section of the tutorial. That's the most important variable as it tells the workflow which kind of jobs you are interested in.
Example:
2) freelancer_description: this field is also really important and the results of workflow will completely depend of the upwork_url and the freelancer_description.
Imagine the upwork_url provides frontend jobs, but in the freelancer_description you mentioned you are an AI engineer… Most probably there will not be many offers that the AI will consider suitable for you.
Example:
I'm Arnau, an experienced web scraping engineer. Together with Miguel we founded Blat, where we have developed an AI Agent able to generate web scraping code in minutes. This code scrapes the content of any website and converts it to any JSON structure. We can do that really fast. The way we prefer to opearte is the following:
1) The client gives us the URL(s) they would like to scrape and if possible the JSON structure they expect to receive the data.
2) We generate the web scraping code in minutes and we provide access to the client via API.
Which are the things we do not do? We avoid to do any kind of custom job that contains some of the following red flags (each red flag has a title):
* UNCLEAR_TARGET_DOMAINS: Researching where the data comes from. Specially for those clients that do not know the target websites they want to scrape. If they don't know that's a red flag for us.
* BUILD_EXTRA_PIPELINE: We do not build extra pipelines with our APIs. We only provide you the data in a reliable way so you our your engineer(s) can focuse on building such pipelines, forgetting about maintaining the web scraping part.
* CUSTOM_OUTPUT: We do want to provide your data in a custom way, let's say they want it in CSV, excel sheet, S3 etc. We do not want to do that. We provide access to our data via API, so you can consume it at your own pace.
3) upwork_max_page: the upwork_url provies a limit amount of jobs (50) and they are sorted by recency. In case you want to scrape jobs of page 1, 2, 3 … you can do it just updating the `upwork_max_page`. We recommend to set this to 1 and execute the workflow each hour or so.
4) blat_api_key: the current workflow uses the Blat services to extract the HTML content and parse it, so you do not have to do it. In case you want a blat_api_key you can ask for it in this link (takes no more than 1 minutes, you only need to give us a mail where we will send you the blat_api_key).
5) slack_hook_url: the current workflow sends the results via Slack (but you could easily send it to RSS, mail etc). You can send messages to your slack channel using webhooks. Here an example to generate your webhook in slack. The slack_hook_url has this format:
6) slack_channel: this is the channel where you are sending the webhook messages so it is related to 4)
7) slack_username and slack_emoji just in case you want to customize your slack messages a bit :)
Impact of this solution
Consider there are only 24 new job offers in Upwork each day (one per hour) for your specific upwork_url. If you want to read all job posts and take a decision for each job if you want or not to apply, it might take easily 5 minutes per job. These are 120 minutes, so 2 hours.
These are not only 2 hours saved for each freelancer on this planet. But 2 hours of a boring job (which is even cooler to automate). Specially, because you already know that you would not be interested in a good amount of the jobs posted there… Who wants to spend time working on that? Well, the truth is that if you want to get money as a freelancer, you need to get work done, and to get work done you need to find jobs that are good fit for your skills.
Imagine all the cool automations you could do based on the information available on the internet? Literally, sky's the limit! Blat is here to help you. We will be happy to hear from you and the data you would need to feed your automations. If you know the url that you would like to scrape, just send a request here and we will come back to you with a solution :)
Questions / Follow - Ups
Do you have any question? Would you like to brainstorm new possible automations with us or propose alternatives? Do not hesitate to get in touch with us :)